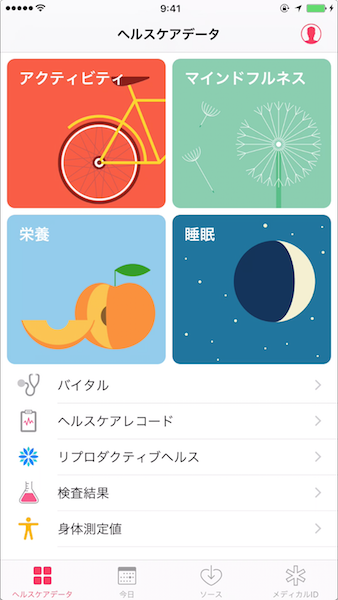
Android WearやApple Watchが出始めの頃は楽しんで着けていたのですが、やはり時計は気に入ったものをしたいので活動量計としても使わなくなってしまいました。活動量計を着けなくても日常持ち歩いているiPhoneには標準でヘルスケアデータを記録できるアプリがインストールされています。データも溜まってきたのでiPhoneから書き出してデータ分析用に使ってみたいと思います。
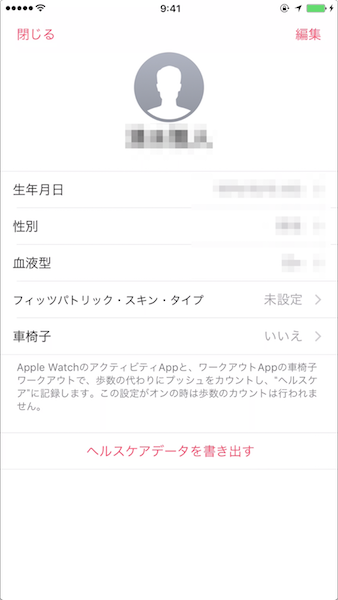
iPhoneからヘルスケアデータを書き出す iPhoneアプリのヘルスケアを開き右上のプロファイルアイコンをタップします。
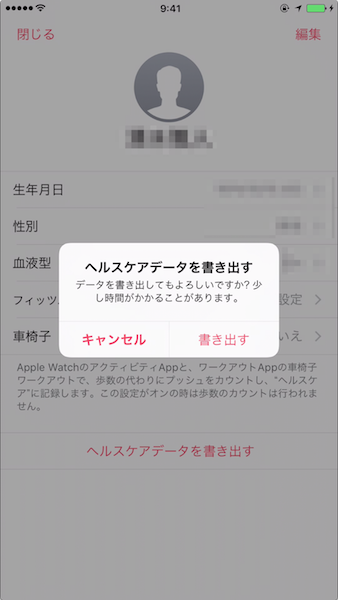
プロファイルページにあるヘルスケアデータを書き出すをタップします。書き出すをタップします。
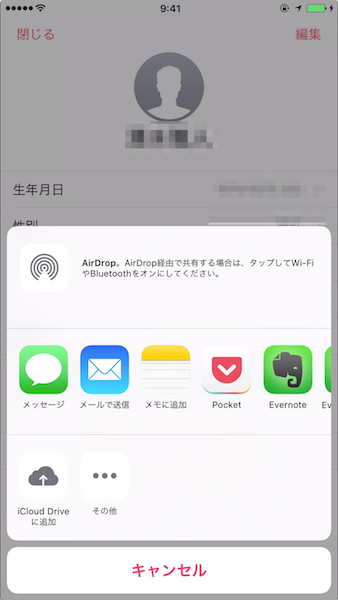
ヘルスケアデータを書き出したいサービスをタップします。
書き出したデータ.zipのファイル名でアーカイブが保存されます。
CSVコンバーター ヘルスケアデータは書き出したデータ.zipの中にあるXML形式の書き出したデータ.xmlファイルです。歩数データはエクセルで管理しているのでコピー&ペーストしやすいようにCSVにコンバートするスクリプトを書きました。ここ からリポジトリをcloneします。
$ git clone https://github.com/masato/health-data-csv.git $ cd health-data-csv
書き出したデータ.zipファイルをcloneしたディレクトリにコピーします。macOSの場合iCloud Driveは以下のディレクトリになります。パスに半角スペースがあるためダブルクォートします。
$ cp "$HOME /Library/Mobile Documents/com~apple~CloudDocs/書き出したデータ.zip" .
convert.pyはZipファイルからヘルスケアデータのXMLを取り出し歩数を日別に集計してCSVファイルに出力するPythonスクリプトです。typeをHKQuantityTypeIdentifierStepCountに指定してRecord要素から歩数データだけ抽出しています。Pythonによるデータ分析入門 ―NumPy、pandasを使ったデータ処理 を勉強しているところなのでデータ分析ツールのpandas を使い集計とCSVへの書き出しを実装してみます。Python 3 で日本語ファイル名が入った zip ファイルを扱う の記事によると書き出したデータ.xmlのように日本語ファイル名はcp437でデコードされるようです。
convert.py from lxml import objectifyimport pandas as pdfrom pandas import DataFramefrom dateutil.parser import parsefrom datetime import datetimeimport zipfileimport argparseimport sys, osdef main (argv ): parser = argparse.ArgumentParser() parser.add_argument('-f' , '--file' , default='書き出した.zip' , type =str , help ='zipファイル名 (書き出した.zip)' ) parser.add_argument('-s' , '--start' , action='store' , default='2016-01-01' , type =str , help ='開始日 (2016-12-01)' ) args = parser.parse_args() if not os.path.exists(args.file): print('zipファイル名を指定してください。' ) parser.print_help() sys.exit(1 ) zipfile.ZipFile(args.file).extractall() parsed = objectify.parse(open ('apple_health_export/書き出したデータ.xml' .encode('utf-8' ).decode('cp437' ))) root = parsed.getroot() headers = ['type' , 'unit' , 'startDate' , 'endDate' , 'value' ] data = [({k: v for k, v in elt.attrib.items() if k in headers}) for elt in root.Record] df = DataFrame(data) df.index = pd.to_datetime(df['startDate' ]) steps = df[df['type' ] == 'HKQuantityTypeIdentifierStepCount' ].copy() steps['value' ] = steps['value' ].astype(float ) if args.start: steps = steps.loc[args.start:] steps_sum = steps.groupby(pd.TimeGrouper(freq='D' )).sum () steps_sum.T.to_csv('./steps_{0}.csv' .format (datetime.now().strftime('%Y%m%d%H%M%S' )), index=False , float_format='%.0f' ) if __name__ == '__main__' : main(sys.argv[1 :])
Pythonスクリプトの実行 スクリプトの実行はDockerイメージはcontinuumio/anaconda3 を使います。データ分析にAnaconda を使うDockerイメージです。Jupyter もインストールされています。-fフラグでヘルスケアから書き出したカレントディレクトリにあるzipファイル名を指定します。-sフラグはCSVにコンバートするレコードの開始日を指定できます。
$ docker pull continuumio/anaconda3 $ docker run -it --rm \ -v $PWD :/app \ -w /app \ continuumio/anaconda3 \ python convert.py -f 書き出したデータ.zip -s 2016-12-01
カレントディレクトリに「steps_xxx.csv」のような歩数を日別に集計したCSVファイルが作成されました。
$ cat steps_20161212013800.csv 2016-12-01,2016-12-02,2016-12-03,2016-12-04,2016-12-05,2016-12-06,2016-12-07,2016-12-08,2016-12-09,2016-12-10,2016-12-11 7217,8815,2260,1828,3711,6980,7839,5079,7197,7112,2958